
Over the last few months I went deep burning ~$1,000/month on tokens building various ‘agent-native’ products and trying new things.
I finally realized what ‘agent-native’ means through trial and error. I couldn’t believe how simple it was. I’ll explain the gist here to save you the hassle, and hopefully you’ll use it to build something awesome.
What does agent-native mean?
Current (pre-AI) software assumes the human is the operator. But agent-native software assumes the agent is the operator and the human supervises.
Trust is the linchpin. And as trust (confidence in output) increases, the leash gets longer. That is the new success metric.
Current software is predicated on human-operator assumptions, and much of it will get rebuilt on new primitives.
The SaaS vibe check: Is it agent-native?
To know if something feels agent-native, ask yourself:
Would you trust AI agents to operate reliably in SaaS apps like your CRM, reporting, accounting, HR, etc. apps?
If the answer is no, it’s not feeling agent-native.
Is this subjective and vibe-y? Yes, but in the end that’s what it’ll take to get customers to say yes. We can build the most magnificent architecture, but it won’t get a yes until customers feel they can trust it.
Once the answer is the smallest yes, continuously growing the agent’s scope through earned trust becomes the new measure of progress. So be smart about picking your first target.
Note: Not blind trust, but under supervision, receipts, and reversible execution. More on this later.
This post focuses more on the technical side, but the experience of imparting trust is equally important.
Why this is worth solving
This is one of the gaps between where we are now and the massive productivity increases promised by enterprises and small businesses adopting AI en masse.
So we’ll focus on productivity software here since that’s the biggest value unlock, and also the next phase of SaaS.
The opportunity
The opportunity for founders in any vertical is clear: What would make that a yes? That’s the vision for agent-native software. A lot has to be reinvented. Example loop for $vertical:
- Build agent-native SaaS app for $vertical, initially focused on narrow, highest confidence set of tasks (e.g., dedupe leads, draft follow-ups, log call notes).
- Built-in guardrails (harness) give users confidence to let the agent perform tasks because everything is a draft until the user approves.
- Approvals/rejections/modifications across users help the SaaS founders understand what is universally true vs. what is true for the company vs what is user preference.
- This feedback loop creates different layers of rules over time, which becomes IP and lock-in for the SaaS app. Users become attached because it works exactly how they want.
- The experience gets better and agents take on more responsibility as the rules improve. There are step changes as new models are released from various providers, which easily slot in.
You can imagine how this process continues across all verticals. Agents become so competent that just about anyone can be trained for any job because the agent provides instant feedback and endless learning scenarios with infinite patience.
So just ask:
What would give my customer confidence to let the agent take over?
Then solve it. Simple, but not easy.
But how?
This is the root of what I’ve been working on the last few months.
My meandering path
I didn’t set out to solve this, but rather stumbled across it. I’d been investing in AI since 2023 and was increasingly frustrated by the gap between AI hype and real output. My path of discovery was building:
GlassAlpha (OSS Python CLI) to explore AI interpretability/explainability and learned just how capable current models were.
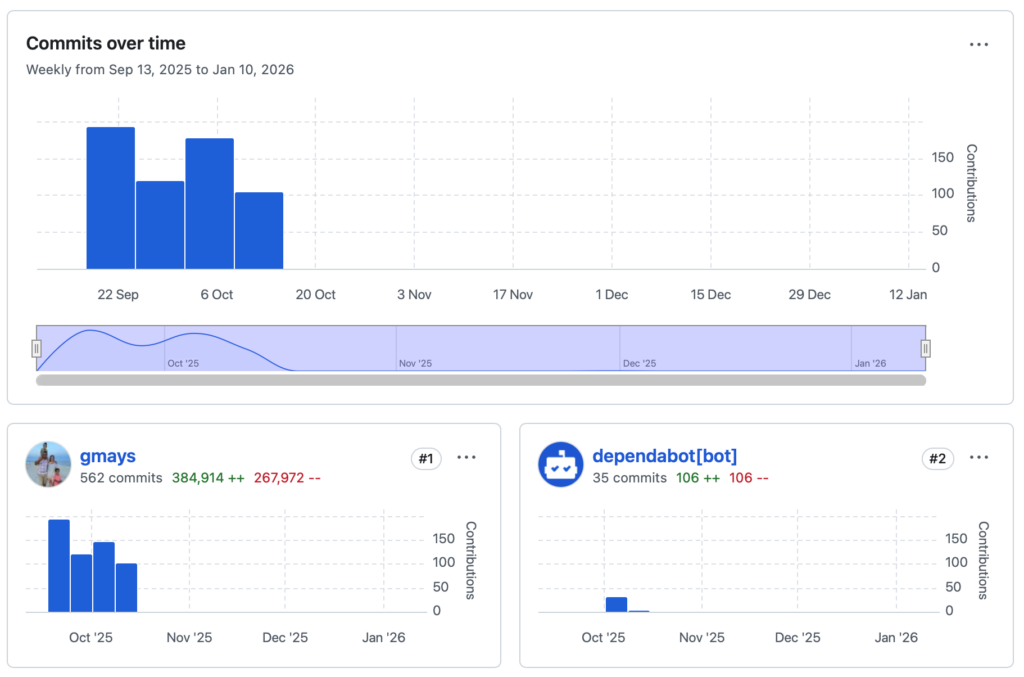
AlignTrue Sync to steer models by syncing rules (directives) across agents, repos and teams
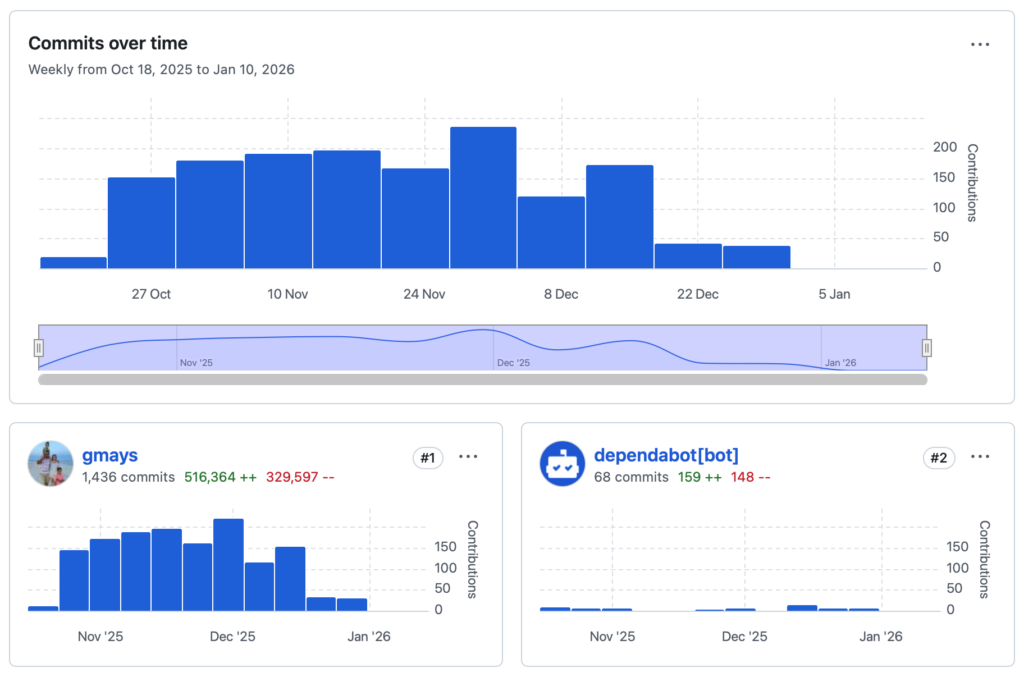
AlignTrue Platform to be an AI/agent-native ops platform, the Salesforce or other <enter-legacy-saas-here> killer starting with a productivity tool, then a CRM and other stuff since every next product was easier.
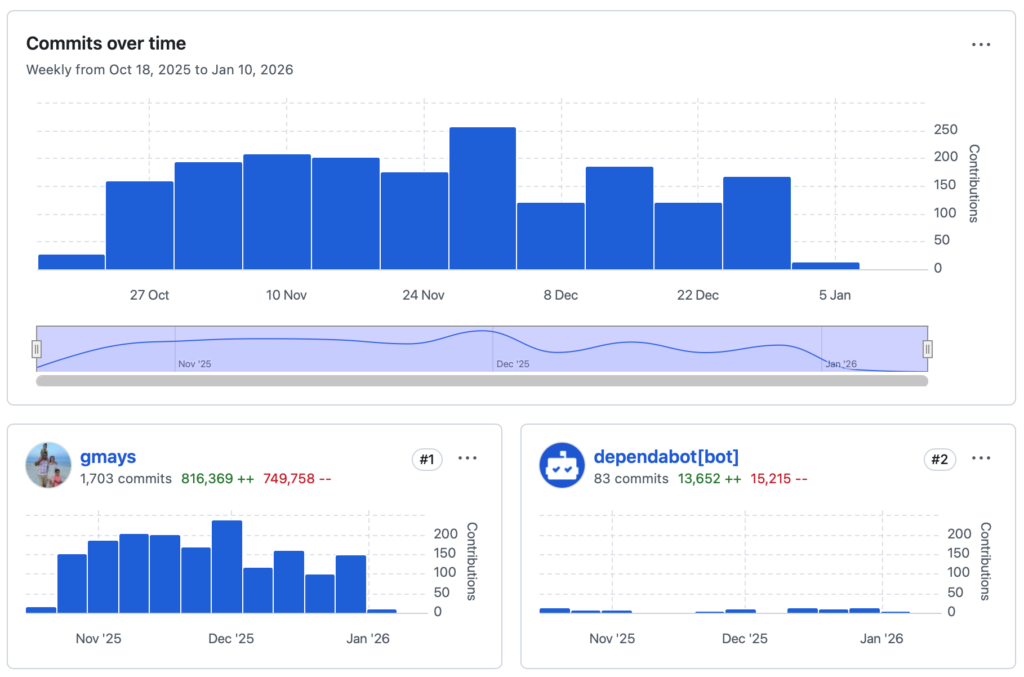
But for real agentic software to go deep, it has to be unique to every vertical, company, team and role because the last mile is unique. Especially because there’s no fuzzy human layer to smooth the rough edges.
And it must continuously evolve as AI models and capabilities improve.
As users trust it with more responsibility, it’ll further bend the curve of what’s possible, reshaping everything around it, because the other agent-native software becomes more capable as well.
I glimpsed the future and it was fucking amazing.
But way too much to build solo.
So I picked a micro-niche that’s fun and interesting to me, forked the agent/AI-native kernel and am focused on that now.
But there are millions of other niches up for grabs, so maybe the below is useful to help you tackle it.
Building agent-native software
Enough talk. How do we make it happen?
For an app to be trustworthy enough to be agent-native it needs:
- Receipts
- Replayability
- Versioned behavior
- Governance
- Idempotent side effects
- Drift control
TL;DR: It’s not agent-native unless it can be audited, reproduced, rolled back, and safely operated at scale. Otherwise “agent autonomy” becomes “agent liability” which is why enterprise adoption is so slow.
Next, let’s go deep on what this looks like in practice.
What “agent-native” requires in practice
Most people hear “trust” and think “UX”: approvals, undo buttons, better prompts.
That helps, but it’s not the core problem.
The core problem is operability.
A human can’t supervise an agent if the system can’t answer basic questions like:
- What exactly did it do?
- What did it see when it decided?
- Which rule/policy version produced this behavior?
- If we rerun this tomorrow, will we get the same result?
- If it touches the outside world, can we guarantee it won’t do it twice?
- What was the agent’s context graph at the moment it decided (inputs, links, and provenance)?
If you can’t answer those, you don’t have an autonomous operator. You have an unbounded liability generator.
So the software architecture shift is: stop assuming humans are the operator, start assuming agents are the operator with the system as the harness.
A starting point
As mentioned earlier, AlignTrue as my experiment in this repo. For all of my recent projects I borrow parts of it, so maybe it’ll be useful to you too.
We’ll also use it as an example to help explain the concepts. Below is the stack of capabilities that make “trust” real: receipts, replayability, versioned behavior, governance, idempotent side effects, and drift control.
The full system (bird’s-eye)
This diagram is the “whole thing” you’re trying to build. Everything else in this section is just zooming in on each box.
flowchart LR
UserOrScheduler[UserOrScheduler] --> Cmd[CommandEnvelope]
Agent[Agent] --> Cmd
Cmd --> Host[HostDispatcher]
Host --> Handlers[PackHandlers]
subgraph ringA [RingA_Kernel]
Events[(AppendOnlyEventLog)]
Proj[Projections]
end
Handlers --> Events
Events --> Proj
subgraph artifacts [Artifacts_Receipts]
Qry[QueryArtifact]
Der[DerivedArtifact]
end
Proj --> Qry
Qry --> Der
Der --> Cmd
subgraph decisionClock [DecisionClock]
Traj[TrajectorySteps_HashChained]
end
Host --> Traj
Handlers --> Traj
Der --> Traj
subgraph egress [Egress_FencedWrites]
Safety[SafetyClassGate]
Outbox[(OutboxQueue)]
Ext[ExternalSystem]
EgressReceipt[EgressReceipt]
end
Cmd --> Safety
Safety --> Outbox
Outbox --> Ext
Ext --> EgressReceipt
EgressReceipt --> Events
subgraph ringB [RingB_Platform]
Sim[Simulation_EvidenceBacked]
end
Proj --> Sim
Traj --> Sim
Sim --> DerHere’s the mental model:
- Events and projections are the state clock
- Artifacts and trajectories are the decision receipts
- Egress is fenced
- Simulation lets you preview behavior before you trust it.
Together, this forms a versioned context graph: what the agent knew, why it acted, and what changed. Next we’ll look at each layer.
Layer 1: Event envelopes (receipts)
Problem
You can’t audit what you didn’t capture, and you can’t supervise what you can’t replay.
Traditional apps log “stuff that happened” as an afterthought. Agent-native apps treat every state transition as a first-class receipt.
Pattern
Use explicit envelopes with the fields you need for supervision:
- Time: what time did it happen at the source vs when your system saw it?
- Causality: what triggered this? what chain did it belong to?
- Actor: was it a human, service, or agent?
- Capability: what was it allowed to do at that moment?
Also, separate Commands from Events:
- Command = intent (“try to do X”)
- Event = fact (“X happened”)
That separation is what lets you do governance and approvals cleanly, and what makes replay meaningful.
flowchart LR Cmd[CommandEnvelope_intent] --> Dispatcher[DispatchCommand] Dispatcher --> Handler[CommandHandler] Handler --> Outcome[CommandOutcome_acceptedOrRejected] Handler --> Events[EventEnvelope_facts] Events --> Log[(AppendOnlyEventLog)] Outcome --> Log
Why: Receipts = trust
Receipts are the substrate for trust. Without them:
- approvals become vibes
- debugging becomes storytelling
- “agent autonomy” becomes “agent got lucky”
Source: https://github.com/AlignTrue/aligntrue
- Kernel contracts:
core/ - Command dispatch + outcomes:
host/(runtime) +packs/*(handlers)
Layer 2: Projections (replayability)
Problem
If your system state can’t be rebuilt from scratch, you can’t prove anything about it.
You can’t confidently:
- debug weird agent behavior
- roll back changes
- migrate safely
- run counterfactuals (“what if we changed the policy?”)
Pattern
Make the write path and read path different on purpose:
- Write truth = append-only event log
- Read truth = projections (materialized, queryable views)
Projections are deterministic functions of events:
- same events
- same ordering rules
- same projection version
→ same state
flowchart LR Log[(AppendOnlyEventLog)] --> Order[CanonicalOrdering] Order --> PDef[ProjectionDefinition_versioned] PDef --> State[ProjectionState] State --> Query[AgentOrUIQueries] Log --> Rebuild[RebuildFromScratch] Rebuild --> State
Why: We think → we can prove
Replayability is what converts “we think the agent did the right thing” into “we can prove and reproduce what happened.”
It also changes how you ship: instead of patching mystery state, you can:
- rebuild
- diff outputs
- verify determinism in CI
Source: https://github.com/AlignTrue/aligntrue
- Projections:
core/ - Apps/UX querying projections:
apps/*andui/
Layer 3: Query + derived artifacts (versioned behavior)
Problem
“The AI decided X” is meaningless without knowing:
- what it looked at
- what it filtered out
- what it believed the world state was at that time
- which policy/prompt/tooling version produced the decision
If you don’t capture that, you can’t do drift control or audits. You can’t even have a productive argument about failures, because there’s nothing concrete to point at.
Those artifacts and their lineage edges are the backbone of the context graph. It’s how you answer “why did it do that?” with concrete pointers instead of vibes.
Pattern
Treat “retrieval” and “decision” as receipts too.
- Query artifact: a deterministic, hashable record of what the agent inspected (references + snapshot semantics)
- Derived artifact: a deterministic, hashable record of what it decided, including lineage (input hashes, policy version, tool versions)
flowchart LR Proj[ProjectionState] --> Qry[QueryArtifact_whatISaw] Qry --> Der[DerivedArtifact_whatIDecided] Der --> Cmd[CommandEnvelope_nextAction] Qry --> StoreQ[(ArtifactStore_JSONL)] Der --> StoreD[(ArtifactStore_JSONL)] Der --> Link[Lineage_inputHashes_policyVersion_toolVersions]
Why: Versioned behavior
This is how you get versioned behavior without pretending prompts are magic.
If the system can point to a derived artifact that says:
- “these were the inputs”
- “this was the policy version”
- “this was the decision”
then behavior is no longer a ghost. It’s a named, replayable, diffable object.
Source: https://github.com/AlignTrue/aligntrue
- Artifacts (query/derived) + stores:
core/ - Policies / prompts / pack logic:
packs/*(and wherever you keep governed behavior)
Layer 4: Trajectories (governance + drift control)
Problem
Even if you capture events, you can still miss the “why” and the “how”.
Events tell you what happened. They don’t necessarily tell you:
- what alternatives were considered
- what evidence was weighed
- where the model was uncertain
- where the system applied redaction/summarization
- where a human edited/overrode
Also: agents don’t just do “one action.” They do sequences. If you can’t see the sequence, governance devolves into guesswork.
Pattern
Capture a decision clock alongside the state clock.
- State clock: events → projections (facts)
- Decision clock: trajectories → outcomes (how decisions unfolded)
Trajectories are hash-chained steps (tamper-evident sequencing), with provenance labels like observed/inferred/asserted.
flowchart LR Start[trajectory_started] --> S1[step_seq_1_step_id_hash] S1 --> S2[step_seq_2_prev_step_hash] S2 --> S3[step_seq_3_prev_step_hash] S3 --> End[trajectory_ended] note1[Provenance_observed_inferred_asserted] --> S2
You can also think of it as a “flight recorder” for decisions:
- bounded
- structured
- redactable
- replayable
Why: Control drift
This is where drift control becomes possible, because you can compare not just outcomes, but decision paths.
When behavior changes, you can answer:
- did the agent consult different evidence?
- did policy version change?
- did the system redact differently?
- did the agent’s confidence shift?
- did the action sequence diverge?
Source: https://github.com/AlignTrue/aligntrue
- Trajectory capture/runtime:
host/ - Trajectory-aware domain logic:
packs/* - Trajectory projections:
core/
Layer 5: Safety classes + egress fencing (idempotent side effects)
Problem
Internal state is easy to fix. External side effects are not.
The agent can always hallucinate “I already sent it” or “I didn’t send it” unless the system can prove:
- what was attempted
- what actually happened
- whether it happened once
At-least-once delivery is reality (retries, timeouts, dupes). So if your write path isn’t idempotent, you will eventually:
- send duplicate emails
- create duplicate tickets
- double-pay invoices
- spam a customer
- get your API keys revoked
Pattern
1) Classify actions by safety:
READWRITE_INTERNALWRITE_EXTERNAL_SIDE_EFFECT
2) Route external writes through a fenced pipeline:
- approvals (human or policy)
- idempotency keys
- outbox for retries
- explicit receipts
flowchart LR Cmd[CommandEnvelope] --> Classify[SafetyClassGate] Classify -->|READ| ReadOp[ReadOperation] Classify -->|WRITE_INTERNAL| IntWrite[InternalWrite] Classify -->|WRITE_EXTERNAL_SIDE_EFFECT| Hold[ApprovalOrPolicyGate] Hold --> Outbox[(OutboxQueue_idempotent)] Outbox --> Ext[ExternalSystem] Ext --> Receipt[EgressReceipt] Receipt --> Events[(AppendOnlyEventLog)]
Why: Autonomy, not liability
This is the line between “agent autonomy” and “agent liability.”
If you don’t fence side effects, you’ll do what everyone does:
- keep the agent on a short leash forever
- ship “assistants” instead of operators
- blame the model for what is actually a systems problem
Source: https://github.com/AlignTrue/aligntrue
- Egress / fencing / idempotency patterns:
core/+host/ - Provider integrations (ingress-only by default):
connectors/*
Layer 6: Simulation
Problem
Even with receipts and governance, you still have a human problem: Humans don’t want to approve a million micro-actions forever. I don’t, you don’t, nobody does.
To scale trust, you need to:
- preview behavior
- estimate risk
- surface precedents
- make approvals faster with evidence
Pattern
Use the data you’re already capturing (projections + trajectories) to answer “what if” questions deterministically and conservatively:
- show similar past trajectories (precedents)
- estimate likely transitions/outcomes
- give a confidence heuristic based on sample size, recency, variance
- never pretend it’s causal truth, treat it as evidence-backed prediction
flowchart LR Proposed[ProposedChangeOrAction] --> Features[ExtractFeatures] Features --> Sim[SimulationEngine_algorithmVersioned] Proj[Projections] --> Sim Traj[Trajectories] --> Sim Sim --> Evidence[Evidence_trajectoryIds_matchedSignals] Sim --> Conf[Confidence_sampleSize_recency_variance] Evidence --> Decision[HumanOrPolicyDecision] Conf --> Decision
Why: Scaling trust
Simulation is what turns the harness from “seatbelt” into “autopilot trainer.”
It makes supervision cheaper:
- approvals get faster
- humans learn what the agent will do
- policies can be promoted safely
- behavior changes can be validated before they ship
Source: https://github.com/AlignTrue/aligntrue
- Simulation + evidence retrieval:
core/(Ring B) - Domain-specific behavior:
packs/*
Making agent-native a reality
We can summarize the architecture as:
- Receipts: event envelopes + artifact envelopes
- Replayability: event log + deterministic projections
- Versioned behavior: artifacts with lineage + versioned policies
- Governance: actors/capabilities + trajectories + explicit outcomes
- Idempotent side effects: safety classes + outbox + receipts
- Drift control: compare decision paths + inputs + versions, not vibes
That’s what it takes to let an agent operate inside a real product without rolling the roulette wheel.
If you want a starting point, that’s exactly what this repo is: an agent-native kernel (Ring A) with the next layer (Ring B) to make trust compound over time.
Fork it, delete what you don’t need, and build on top of the harness.
A caution
This stack is heavy and easy to overbuild. AlignTrue was an exercise to push the limits, so only copy the parts you need (treat it as a reference architecture).
For example, for my latest project I only used the follow parts and modified them to be much more lightweight:
- Safety classification:
SafetyClass(READ/WRITE_INTERNAL/WRITE_EXTERNAL_SIDE_EFFECT) +TargetSurface(KERNEL/WORLD/EXTERNAL) - Actor pattern:
ActorRefwithActorType(HUMAN/AGENT/SYSTEM) for identity and authorization - Deterministic hashing:
canonicalize()for stable JSON +contentHash()for idempotency keys - Intent flow: ActionIntent lifecycle (PENDING → APPROVED/REJECTED → EXECUTING → EXECUTED) with race-safe transitions
- Authorization rules:
assertCanApprove()(humans only) +assertCanExecute()(humans/system, matching approver) - Dry-run:
DryRunResultto preview kernel commands/tool calls before execution - Provenance tracking:
AiRun+AiRunStepwith correlation IDs and actor attribution
The key thing is to understand the why of each layer, understand the needs of your project and adjust accordingly. Getting it right is important because it’s hard to change later once the assumptions are baked-in.
Brief note on existing software co’s
I was going to share notes on how this could work for existing (pre-AI) companies, but this is already longer than planned. If there’s interest, I’ll post something about it.
New companies are the best positioned because they’re starting with a clean slate, but existing SaaS companies also have a path forward if they’re willing to move fast enough.
What’s next
There’s a sort of distributed search happening now, with thousands of individuals and startups trying thousands of things figuring out what the next frontier is.
Maybe what I shared above is on the right path, maybe not, but man is the journey fun. It opened my mind to the immense opportunity over the next decade.
If we pause for a second and assume we trust AI enough to operate with minimal supervision, it changes everything. In response, everything else changes. It’s a feedback loop that just blows open everything we know today.
We’re insanely lucky to be alive right now with the ability to build. So do it.